IBM در جهت توسعه فناوری تشخیص چهره بیومتریک گام برمیدارد

آیبیام با استفاده از دادههای یک میلیون چهره، درتلاش است تا سوگیری نتایج را در سیستم تشخیص چهره مبتنی بر هوش مصنوعی به حداقل برساند.
سوگیری در نتایج مربوطبه رمزگذاری سیستم های مبتنی بر یادگیری ماشینی و بهصورت کلی در سیستمهای مبتنی بر هوش مصنوعی، تقریبا اجتنابناپذیر است. اما ظاهرا میتوانیم امیدوار باشیم، تلاش آیبیام وضعیت را بهتر از قبل میکند.
IBM امیدوار است تا با استفاده از دیتابیس جدید شامل یک میلیون چهره که بازتابی از چهرههای موجود در دنیای واقعی هستند؛ بتواند سوگیری نتایج در سیستمهای تشخیص چهره را به حداقل برساند.
فناوری تشخیص چهره کاربردهای متنوعی دارد و از باز کردن قفل گوشیهای هوشمند تا باز کردن در ورودی منزل مورد استفاده قرار میگیرد. همچنین از فناوری تشخیص چهره برای سنجش وضعیت و حالتهای ذهنی کاربر یا حتی احتمال فعالیت وی در حوزههای جنایتکارانه نیز استفاده میشود. البته برخی معتقدند که چنین کاربردهایی هنوز در فناوری تشخیص چهره قابل استفاده نیستند. از سوی دیگر، فناوری تشخیص چهره در برخی موارد حتی برای امور سادهای همچون تأیید هویت کاربر نیز با مشکلاتی روبهرو است. گاهی، فناوری تشخیص چهرهی بیومتریک برای تأیید هویت افرادی با رنگ پوست خاص یا افراد با سنهای مختلف نمیتواند سربلند از آزمون بیرون بیاید.

البته علت بروز چنین مشکلاتی، کمی پیچیده است. یکی از دلایل اصلی ناتوانی عملکرد فناوری تشخیص چهره در برخی حوزهها، آن است که بسیاری از توسعهدهندگان و سازندگان اصلا به چنین موضوعاتی فکر نمیکنند. در نتیجه دادههای مربوطه را برای سیستم تعریف نکرده و درصدد رفع چنین مشکلاتی از سیستم خود تلاشی خاصی انجام نمیدهند.
اما چنین خطاهایی باید مورد توجه همهی دستاندرکاران امر قرار گیرد و باید همهی افراد و گروههای درگیر در جهت توسعه و رفع مشکلات گام بردارند. اما از سوی دیگر نباید موضوع مهم دیگری را فراموش کنیم. دادههای واقعی نیز برای عملکرد صحیح سیستم، بسیار حائز اهمیت هستند. درحالیکه دادههای مربوطبه همهی افراد به سیستمهای مبتنی بر فناوری تشخیص چهره وارد نشدهاند و چنین سیستمهایی، دادههای مربوطبه چهرهی همهی کاربران را ندارند؛ چگونه میتوان به الگوریتم بینایی کامپیوتری آموزش داد تا بهدرستی بتواند همهی افراد را شناسایی کند؟
بیشک محدودیتهایی برای ورود داده در هر سیستمی وجود دارد. اما اگر بتوان سیستمی دراختیار داشت که دادههای متنوعی داشته باشد و بهصورت مؤثر و سیستماتیک از دادههای موجود استفاده کند، به هدف خود نزدیک شدهایم و خطاهای سیستم کمتر خواهد شد. شرکت آیبیام درتلاش است تا مجموعهای از میلیونها تصویر با تنوع چهرههای مختلف یعنی DiF یا Diversity in Faces را ایجاد کند. در مقالهی مربوطبه معرفی این مجموعه تصاویر آمده است:
برای آنکه فناوری تشخیص چهره بتواند دقیق و درست عمل کند، دادههایی که به سیستم آموزش داده میشود باید بهاندازهی کافی متنوع باشند و بتوانند تنوع چهرههای مختلف را پوشش بدهند. در نتیجه نیاز به دادههای متنوع و در حجم بالایی داریم تا بتوانند مولفههای مختلف را پوشش بدهند و تفاوتهای ذاتی که در چهرههای مختلف وجود دارند را شناسایی کنند. تصاویر باید بتواند تنوع ویژگیهای مربوطبه چهرههای افراد مختلفی که در سراسر جهان زندگی میکنند را بهخوبی نشان دهند.
چهرهها از مجموعهی دادههای عظیم ۱۰۰ میلیون تصویری (Flickr Creative Commons) تهیه شدهاند. از این طریق، سیستم یادگیری ماشین میتواند تصاویر متنوعی از چهرههای مختلف را در اختیار داشته باشد. درنهایت تصاویر تفکیک و کراپ میشوند و از آن زمان به بعد کار اصلی شروع خواهد شد.
از آنجایی که این مجموعهی تصاویر، بهوسیلهی سایر الگوریتمهای یادگیری ماشین مورد استفاه قرار میگیرد؛ درنتیجه باید هم متنوع باشند و هم بهدرستی برچسبگذاری شده باشند. بنابراین مجموعهی DiF با بیش از یک میلیون تصویر چهره، متادیتایی بههمراه خودش دارد که موارد مختلفی را توصیف میکند. مواردی همچون فاصلهی بین چشمها، اندازهی پیشانی و همهی جزییات مشخص میشود. تمام این اندازهگیریها منجر به ایجاد faceprint میشود که سیستم درنهایت از آن استفاده میکند تا بتواند دادههای مربوطبه چهرهی فرد را با دادههای کاربر دیگری مطابقت بدهد.

اما درنظر داشته باشید که همهی دادههای مربوطبه سنجش، ممکن است برای شناسایی و تشخیص چهره مورد استفاده قرار نگیرند. بنابراین تیم تحقیقاتی IBM، مجموعهای از دادههای سنجش را عمومی و برخی دیگر را بهصورت تخصصی مورد بررسی قرار میدهد. مثلا در برخی موارد نسبت بین دو مولفهی اندازهگیریشده از چهرهی فرد مورد توجه قرار میگیرد. برای مثال، نسبت ناحیهی بالای چشم به ناحیهی زیر بینی بهعنوان یک مولفه درنظر گرفته میشود. رنگ پوست و همچنین میزان کنتراست و تنوع رنگ پوست نیز جزو ارزیابیها قرار دارند.
یکی دیگر از موضوعات مورد توجه، مسئلهی جنسیت است. جنسیت بهصورت باینری سنجش نمیشود و برای جنسیت مولفهی غیرباینری درنظر گرفته شده است و مقیاسی بین صفر و یک را محاسبه میکند. در نتیجه برای مقیاس زنانگی و مردانگی، پارامتر باینری ارائه نشده است.
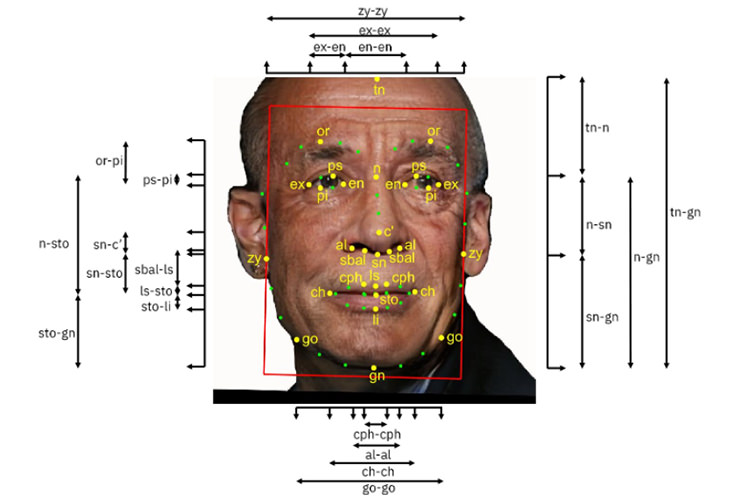
مولفهی سن سوژه نیز بهصورت اتوماتیک تخمین زده میشود، اما برای دو مولفهی جنسیت و سن، امکان ارائهی توضیحات اضافی برای سیستم درنظر گرفته میشود و درنهایت تست واقعیتسنجی صورت میگیرد. از آنها خواسته میشود تا چهرهها را براساس جنسیت زن و مرد برچسبگذاری کنند و سن را حدس بزنند. باتوجه به اینکه حضور تصمیمگیرندهی انسانی برای این بخش تعریف شده، ممکن است مجددا با موضوع سوگیری رمزگذاریها مواجه شویم. اما درنظر داشته باشید که تمامی سنجشها، قصد دارد دامنهی وسیعتری برای آموزش الگوریتمهای مبتنی بر فناوریهای مربوطبه تشخیص چهره به سنجشهای قبلی اضافه کند.
ممکن است تعجب کنید که چرا نژاد یا قومیت در طبقهبندی مولفهها درنظر گرفته نشده است. جان آر. اسمیت که رهبری این پروژه را در آیبیام برعهده دارد، در ایمیلی توضیح داد:
باوجود اینکه موضوع قومیت بیشتر به حوزههای فرهنگی مربوط میشود و مقولهی نژاد بیشتر به حوزههای بیولوژی ربط پیدا میکند، اما معمولا قومیت و نژاد بهاشتباه بهجای یکدیگر و مورد استفاده قرار میگیرند. البته باید درنظر داشته باشیم که تعریف مرز و حدود برای قومیت و نژاد کار سادهای نیست و حتی برچسبگذاری که برای این دو درنظر گرفته میشود، مجددا مولفههای ذهنی هستند که در مطالعات قبلی به آن پرداخته شده است و مسایل مربوطبه خودش را دارد. در تحقیق حاضر، تصمیم گرفتیم روی محورهایی با قابلیت کدگذاری تمرکز کنیم که قابل اعتماد باشند و همچنین بهصورت پیوسته بتوان برای آن مقیاس تعریف کرد و مولفههای قابل تجزیهوتحلیل داشته باشد. اما ممکن است در آینده دستهبندی مولفههایی که بهصورت ذهنی بررسی میشوند را نیز در دستور کار خود قرار دهیم.

با این وجود، حتی با اینکه حدود یک میلیون چهره برای این سیستم درنظر گرفته شده است، هنوز هیچ تضمینی وجود ندارد که این مجموعه نیز بتواند بهاندازهی کافی، نمایندهی تمام تصاویر مربوطبه چهرههای مختلف باشد. این تعداد بالای تصویر از همهی گروهها و زیرگروهها به سیستم مبتنی بر هوش مصنوعی آموزش داده شده تا از ارائهی نتایج سوگیرانه جلوگیری کند. اسمیت در مورد این موضوع توضیح میدهد:
باتوجه به اینکه اولین نسخهی مجموعهی دادهها به سیستم مبتنی بر هوش مصنوعی آموزش داده شده است، هنوز نمیتوانیم در مورد نتایج غیرسوگیرانه با اطمینان کامل صحبت کنیم. اما هدف ما دستیابی به چنین موقعیتی است. برای رسیدن به این هدف اول باید ابعاد تنوع را به سیستم آموزش دهیم. برای انجام این کار ابتدا سعی کردیم دادههای و کدهای مختلف را مورد توجه قرار دهیم. این روند را ادامه میدهیم و امیدواریم بتوانیم در این مسیر به رشد و بالندگی برسیم.
بهعبارت دیگر باید در نظر داشته باشیم که در مسیر رشد و پیشرفت قرار داریم. باوجود همهی خطاها و وعدههایی که هنوز محقق نشدهاند، باید باور کنیم که چه بخواهیم و چه نخواهیم، فناوری تشخیص چهره بهشدت در آینده بیش از اکنون مورد استفاده قرار خواهد گرفت.
سیستمهای مبتنی بر هوش مصنوعی برمبنای دادههای خود بنا نهاده میشوند و برای توسعهی چنین سیستمهایی نمیتواند دادهها را درنظر نگرفت. مانند هر مجموعهی دیگری، DiF نیز کاستیهای خودش را دارد و بهمرور زمان مسیر کاملتر خواهد شد.