گوگل دیتاست آموزش هوش مصنوعی با ۵ میلیون عکس منظره عرضه کرد

گوگل علاوهبر تحقیقات در حوزهی هوش مصنوعی، ابزارهای مورد نیاز این صنعت همچون دیتاستها را نیز برای علاقهمندان آمادهسازی و ارائه میکند.
طراحی سیستمهای هوش مصنوعی که توانایی تشخیص دقیق منظرهها از یکدیگر و شناسایی منظرهی مشابه در عکسهای متعدد را داشته باشند، همیشه موضوع مهمی در زیرمجموعهی تحقیقات هوش مصنوعی گوگل بوده است. چنین سیستمهایی بهعنوان مثال میتوانند آبشار نیاگارا را از آبشارهای عادی دیگر تشخیص دهند یا با دیدن عکس یک منظره در تصویری دیگر، یکسان بودن آنها را بیان کنند.
غول موتور جستوجو سال گذشته Google-Landmarks را ارائه کرد؛ مجموعهای از دادهی منظرهها که گوگل ادعای بزرگترین مجموعهی جهان را روی آن داشت. بهعلاوه آنها ۲ مسابقه به نامهای Landmark Recognition 2018 و Landmark Retrieval 2018 هم برگزار کردند که بیش از ۵۰۰ محقق یادگیری ماشین در آنها حضور یافتند.
گوگل اکنون در مسیر توسعهی مدلهای پیچیدهتر بینایی کامپیوتری در حوزهی تشخیص منظرهها، نسخهی جدیدی از دیتاست مناظر را عرضه کرد. نسخهی جدید که بهنام Google-Landmarks-v2 عرضه شد، دوبرابر تصاویر بیشتر و هفت برابر مناظر بیشتر را در خود جای داده است. بهعلاوه، مسابقات یادگیری ماشین نیز در جامعهی مجازی Kaggle گوگل اجرا شدند. درکنار این موارد، کد منبع و مدل فریمورک Detect-to-Retrieve هم ارائه شد که برای شناسایی منطقهای تصاویر کاربرد دارد.
بینجی کائو و توبیاس ویاند، مهندسان نرمافزار هوش مصنوعی گوگل دربارهی ابزارهای جدید گفتند:
هر دو فرایند شناسایی تصویر و تشخیص شباهتها نیازمند دیتاستی بسیار عظیم خواهد بود که هم تعداد عکسها و هم تنوع منظرهها در آنها بالا باشد. ما امیدوار هستیم که این دیتاست به پیشرفت فناوریهای موجود در شناسایی تصاویر و تشخیص شباهتها منجر شود.
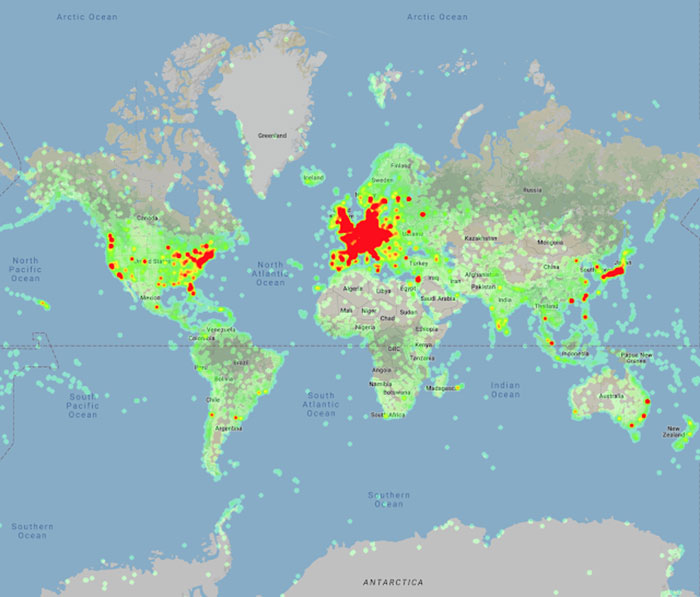
پراکندگی جغرافیایی مناظر موجود در دیتاست Landmark-V2
طبق ادعاهای مهندسان گوگل، Google Landmark V2 بیش از ۵ میلیون عکس از ۲۰۰ هزار منظرهی گوناگون دارد که از عکاسان سرتاسر جهان گردآوری شده است. عکاسهای مورد نظر، عکسهای خود را برچسبگذاری کردهاند. درنتیجه عکسها شامل برچسبهایی همچون برج الخلیفه، پل گلدن گیت، برج پیزا و دیگر مناظر مشهور جهان بودند. محققان گوگل پس از دریافت عکسهای برچسبگذاری شده، آنها را با عکسهای تاریخی و کمترشناختهشده از Wikimedia Commons تکمیل کردند. مخزن مذکور به بنیاد ویکیمدیا تعلق دارد و بهعنوان مخزنی آنلاین برای عکس، صوت و هر نوع محتوای رسانهای رایگان محسوب میشود.
مهندسان گوگل دربارهی فریمورک Detect-to-Retrieve هم توضیحاتی ارائه کردند. مدل منتشرشده که با استفاده از مجموعهای ۸۰ هزار عددی از دیتاست اصلی آموزش داده شد، قابلیت ترسیم جعبههایی پیرامون مناظر و موضوعات مورد نظر را ارائه میکند. چنین ابزاری، اهمیت مناطق چارچوببندیشده را در بررسی یادگیری ماشین افزایش میدهد که منجر به افزایش دقت میشود.
شرکت در هر دو رقابت گوگل در حوزهی یادگیری ماشین برای عموم آزاد است. مسابقهی Landmark Recognition 2019 با هدف طراحی مدلهای هوش مصنوعی تشخیصدهندهی مناظر اجرا میشود. هدف مسابقهی Landmark Retrieval 2019 نیز استفاده از سیستم هوش مصنوی برای پیدا کردن تصاویر یک منظرهی خاص بیان شد. مجموع جوایز مسابقات به ۵۰ هزار دلار میرسد. بهعلاوه برندهها برای ارائهی روشهای خود به کارگاه Second Landmark Recognition Workshop دعوت میشوند که در حاشیهی کنفرانس بینایی کامپیوتری و تشخیص الگوی ۲۰۱۹ در لانگ بیچ کالیفرنیا برگزار خواهد شد.





